# Training a sub 1B LLM for local use in Home Assistant
Tags: AI NLP Home Assistant
Reading time: 4 minutes
Description: (!!Work in progres!!)
# Introduction
TODO
Home-LLM: https://github.com/acon96/home-llm/
Model used: https://huggingface.co/HuggingFaceTB/SmolLM-135M-Instruct Model family description: https://huggingface.co/blog/smollm
Why such a small model: https://arxiv.org/pdf/2310.03003
# Test environment
A quick and dirty HASS Docker setup, since i dont want to copy each model iteration to the PI..
|
|
## Deploying and installing HACS
|
|
- restart the container
- install hacs integration and Local
LLM Conversation plugin - setup the
LLM Conversation plugin - select
Llama.cpp (HuggingFace)as backend - download any model
- use the
Home-LLM (v1-v3)API - try it out
# Preparing the training environment
- create a new conda environment:
conda create --name ai - activate it:
codna activate ai - downgrading the python interpreter since pyo3-ffi v0.21.2 does not support 3.13:
conda install python=3.12 - installing general dependencies:
pip install -r requirements.txt - installing dependencies for the dataset generation:
pip install pandas==2.2.2 datasets==2.20.0 webcolors==1.13 babel==2.15.0 - generate the training dataset:
python3 generate_home_assistant_data.py --train --test --large --sharegpt - installing training dependencies:
pip install datasets==2.20.0 dataclasses==0.6 transformers==4.43.3 torch==2.4.0 accelerate==0.33.0 tensorboard==2.17.0 peft==0.12.0 bitsandbytes==0.43.3 trl==0.9.6
## Train
### Finding prefix and suffix token
|
|
### Train
- sample command:
python3 train.py --run_name smollm_135m_instruct_run01 --base_model HuggingFaceTB/SmolLM-135M-Instruct --bf16 --train_dataset data/home_assistant_train.jsonl --test_dataset data/home_assistant_test.jsonl --learning_rate 5e-6 --batch_size 32 --micro_batch_size 8 --gradient_checkpointing --group_by_length -ctx_size 2048 --save_steps 500 --save_total_limit 10 --prefix_ids 520,9531,198 --suffix_ids 2,198
## Quantize
To use the model with llama-cpp it must be converted to the gguf format.
Also quantize it for inference speed.
git clone https://github.com/ggerganov/llama.cppGGM_CUDA=1 make -j32pip install -r requirements.txt- convert the model to gguf:
python3 convert_hf_to_gguf.py ~/Source/AI/home-llm/models/smollm_135m_instruct_run01/ - quantize gguf to 4 bits using Q4_K_M:
./llama-quantize /home/user/Source/AI/home-llm/models/smollm_135m_instruct_run01/SmolLM-135M-Instruct-F16.gguf /home/user/Source/AI/home-llm/models/smollm_135m_instruct_run01/SmolLM-135M-Instruct-Q4_K_M.gguf Q4_K_M - test inference:
./llama-cli -m /home/user/Source/AI/home-llm/models/smollm_135m_instruct_run01/SmolLM-135M-Instruct-Q4_K_M.gguf -p "you are a helpful assistant"
## Test on HASS
- copy the newly quantized gguf into HASS
- create new service in Home LLM integration
- select
Llama.cpp (existing model)as backend and specify model path in container - copy path into
Local file name - set
LLM APItoHome-LLM (v1-3) - go to voice asistants and add a new assistant
- switch tab to
exposeand make sure that shopping list (or any other entity you want to controll with the model) is exposed - go to the dashboard and open the chat window
- set conversation agent to the new LLM model
# Results
## Training run 01
Results:
{'train_runtime': 1213.0166, 'train_samples_per_second': 35.494, 'train_steps_per_second': 1.109, 'train_loss': 2.8430937607492215, 'epoch': 1.0}
| Parameter | Value |
|---|---|
| learning_rate | 5e-6 |
| batch_size | 32 |
| micro_batch_size | 8 |
Well…
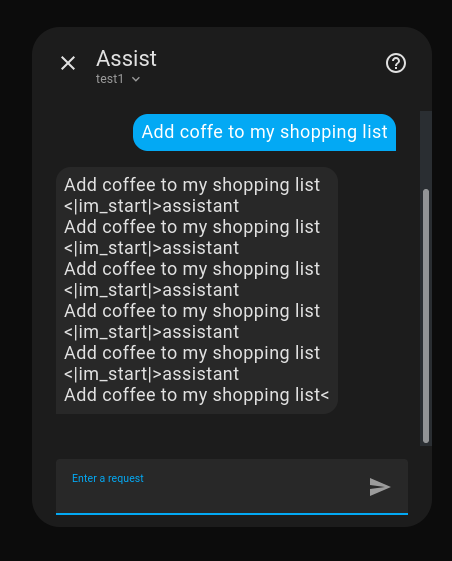
## Training run 02
Results:
{'train_runtime': 1207.0863, 'train_samples_per_second': 35.669, 'train_steps_per_second': 1.114, 'train_loss': 0.08614175222177045, 'epoch': 1.0}
Trying the parameters the model was trained with and quantizing to Q8_0.
According to the HuggingFace Page:
- 1 epoch
- 1e-3 learning rate
- cosine schedule (default in the train.py script)
- warmup ratio 0.1
- global batch size 262k tokens (idk about this one, ignore for now)
| Parameter | Value |
|---|---|
| learning_rate | 1e-3 |
| epochs | 1 |
| warmup_ratio | 0.1 |
| batch_size | 32 |
| micro_batch_size | 8 |
At least the output format is going in the right direction…
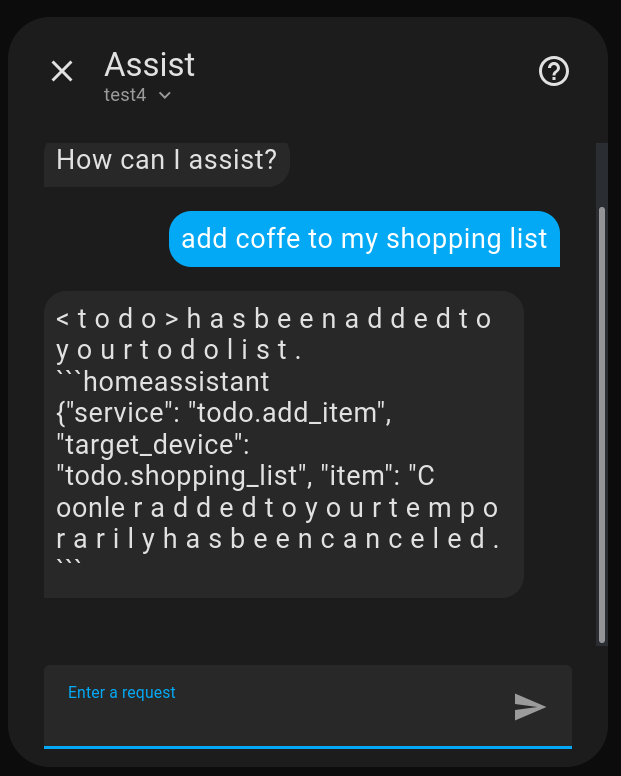
## Training run 03
Results:
{'train_runtime': 1197.7346, 'train_samples_per_second': 35.947, 'train_steps_per_second': 0.144, 'train_loss': 0.22953853764852813, 'epoch': 1.0}
Increasing the batch size to 256, micro batch size to 10 and still using Q8_0.
| Parameter | Value |
|---|---|
| learning_rate | 1e-3 |
| epochs | 1 |
| warmup_ratio | 0.1 |
| batch_size | 256 |
| micro_batch_size | 10 |
Still hallucinating heavily but at least using the right item (well i only altered the batch size so cant expect much to change).
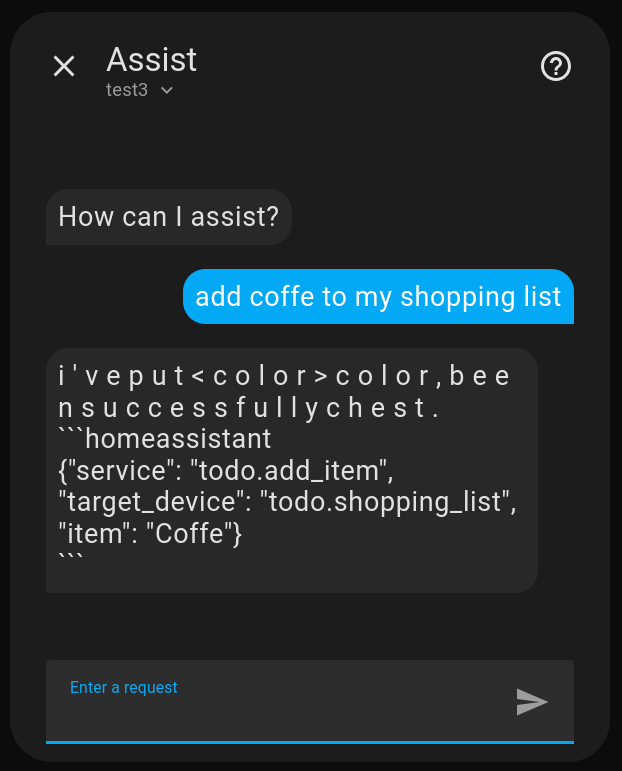
to be continued…